

#30dayofDataStructures


Table of contents


No headings in the article.
I will be sharing what i'll be learning daily about Data structures in the next 30 days here on Hashnode. Please join me in this journey and feel free to check back everyday in the next 30 days as I'll be updating this article daily.
#30daysofDataStructures
Day 1 : Data Structure is used to manage, store, retrieve and manipulate data. Data structures are used to organize data effectively as well as reduce complexities and increase speed.
Types of Data Structures Linear and Non-linear data structures 4 built-in data structures in Javascript: Arrays, Objects, Maps and Sets.
Array: is used to store a list of comma seperated data(strings, numbers, booleans or any data type) in a square bracket which can be manipulated. Syntax:
const age = [10, 39, 42, 13, 57]
- Arrays are usually assigned to a variable.
- Arrays are indexed at 0 (When counting items in an array, the first item takes the number 0, the next takes number 1).
- We can have a value twice in an array
const animals = [ 'rat', 'sheep', 'goat', 'snake', 'sheep'] - Arrays are iterable i.e we can use the for of loop to iterate through the values in an array
const people = ['Rita', 'Sam', 'Dora', 'Hantha'] for (const data of people){ console.log('I am ' + data) } // This will print out all the items in the array - The insertion order of an array is always the same
- You can have different data types in an array
const mixedType = [23, 'Sammy', true, [2, 5, 'Chicken']]
Downside of an array: Deletion and finding of elements can require extra work and it can be performance intensive.
SETS: Set also has to do with managing data. It lets you create object that store unique values of any type.
- Unlike array, duplicate items are not allowed in Set
- Insertion order is not stored i.e you cannot access the data using index but you can using methods like .add, .delete, .has, .forEach e.t.c
- The data in a set can't be accessed using index
- Deletion and finding of elements is fast because the position of a value doesn't matter and
- Sets are iterable just like arrays
- Sets can store data more efficiently because the position of a value doesn't matter.
Syntax:
const animals = newSet()
Check out MDN documentation on Sets here
Arrays OR Sets ? If you would always go through an array to validate if an item exist, Set should be used. If order matters, Arrays should be used.
Day 2 - Linked list: it's similar to array but has it's unique advantages. Elements in a linked list are called nodes and unlike arrays, the nodes in a linked list are only aware of the nodes that comes after them and not before them.
The first element in a linked list is called the head node while the last is called the tail node. Methods that can be used in a linked list
- append(): adds a node to the end of the list.
- prepend(): adds a new node at the beginning of a list. -delete (): as the name implies. Why Linked list If you'll be doing a lot of insertions and deletions, it's advisable to use linked list because unlike arrays, you don't have to specify the size of your list in advance.
There also is the doubly linked list and the circularly linked list The latter points to the previous node unlike singly linked list(points forward only) while the former is okay to use if you don't want to go through the headache of pointing to the previous node just to get to the head node
Day 3 - #30daysofDataStructures Big O notation is a way to measure how efficient a data structure works for different tasks. It's called Big O because the syntax for time Complexity Equation includes a big O and parenthesis - O()
Time Complexity has to do with the amount of time it takes an algorithm to run. Accessing, Searching for, Inserting and deleting an element are the most common functions that can be wanted from a data structure and these functions are scored using the Time Complexity Equation.
O(1)... O(n)... O(log n)... O(n log n)... O(n2)* and O(2n) are all common time complexity equations. The fastest type of time complexity is the constant time O(1). Next is O(log n). They are both efficient and provide fast completion time.
Day 4 - #30daysofDataStructures
Stack: is a sequential access data structure in which we add elements and remove elements using the LIFO(Last In First Out) principle. Meaning, the first element to be added will be the last element to be removed.
A popular example of the LIFO principle is the placing of plates/stones on eachother, the first plate or stone can not be taken out of the stack unless the ones on it are removed starting from the last one to be added.
There's only one way in and out
Methods that can be used in a stack : Push..Pop..Peek..Contains. The Push and Pop are built-in methods. Push is used to add elements to a stack while Pop is used to remove elements from a stack.
names.push("Rita") -> 1st element
names.push("Reeree") -> 2nd element
names.pop() -> will take out "Reeree" from the stack because it's the last element in the stack.
Peek and Contains are used to interact(check for an element,get the value of an element without removing it) with the stack without changing it.
names.peek()
Using .contains and a given argument, the contains method returns a boolean (true or false) if the argument (element) is found in the stack.
names.contains("Reeree") // true
names.contains("Samantha")//false
Day 5 - #30daysofDataStructures
QUEUE : is also a sequential access data structure (it's not randomized). It follows the FIFO(First In First Out) method. Picture the ATM queue🌚, the first person on the queue is always the first to leave.
Unlike the Stack where we add and remove elements from the top, elements are always added from the back(known as the tail) and removed from the front(known as the head) in Queue.
Peek and Contains can also be used in a queue and the other unique methods of the Queue data structure are the Enqueue and Dequeue. They both act like the push and Pop methods in the Stack data structure. Enqueue would add an element from the tail of the queue and as more elements are been pushed in the queue, the initial element becomes the head while Dequeue works like the pop method in the Stack data structure but this time, it takes out element from the head (front) of the Queue.
Another real life example of a queue is the printer🌚(think about it😌)
𝔻𝕒𝕪 𝟞 - #30daysofDataStructures 𝕀 𝕕𝕚𝕕 𝕒 𝕣𝕖𝕧𝕚𝕤𝕚𝕠𝕟 𝕠𝕗 𝕒𝕝𝕝 𝕥𝕙𝕖 𝕕𝕒𝕥𝕒 𝕤𝕥𝕣𝕦𝕔𝕥𝕦𝕣𝕖𝕤 𝕚’𝕧𝕖 𝕔𝕠𝕧𝕖𝕣𝕖𝕕 𝕤𝕚𝕟𝕔𝕖 𝕕𝕒𝕪 𝟙.
Day 7 - #30daysofDataStructures I couldn’t do so much but I looked at hash table also known as hash map. It’s used to store key-value pairs.
I would cover more on hash tables tomorrow.
#30daysofDataStructures
Day 8 - #30daysofDataStructures
Hash table is used to implement mappings of key-value pairs, it works by taking a key, running it through a hash function to return the value.
They are like arrays but the keys are unordered. Hash tables are fast for carrying out the operations of a hashing functions
A hashing function accepts a string as key, converts it to a hash code and maps it into a numeric index
Hashing function supports 3 main operations:
Retrieving a value, given its key
Storing key-value pair Removing or deleting a key-value pair.
Thanks to @IzyPro_ 🙇♀️🙇♀️who helped in explaining hash table and its usecase.
Day 9 - #30daysofDataStructures Hash Collision: occurs when different words/keys hash to the same index. We can manage hash collision using Separate Chaining or Linear Probing.
Separate chaining helps in solving hash collision by using another data structure like an array or Linked list.
Linear Probing manages hash collision by allocating an empty spot for the key&value that's hashing to an index that already has a value. If at index 2, we already have a key-value pair and another key-value pair is hashing to index 2, using linear probing, we'll look for an empty slot and store the new key-value pair.
Methods that can be used in a hash table includes the Set and Get methods.
Set accepts a key and a value as arguments, hashes the key and store the key-value pair in the hash table array via separate chaining.
Get accepts only the key and returns the value of the given key after going through the hash table. If a value for the given key isn't found in the hash table, it returns undefined.
#30daysofDataStructures
Day 10 - #30daysofDataStructures Tree is a data structure that consists of nodes in a parent-child manner. Picture a tree like this: 20 / \ 12 25 / \ / \
The first number(20), is the called the root/top node of the tree Number 12 and 25 are called the children of the tree because they are directly connected to the root. The arrow is called an edge. Siblings are nodes that have the same parents. A real life example of a tree is a folder holding other folders that are holding files or folders in a project in your code editor.
I focused on the two basic types of a Tree, that's the Binary Tree and the Binary Search Tree.
The Binary Search Tree is a type of tree that can hold sorted data and the highest amount of children a BST can hold is 2. The characteristics of a BST:
- Every node to the left of the parent node/children, must have less value.
- Every node to the right must have great value.
This is useful in terms of speed. It makes it easy to get a value without having to go through the whole tree. I also learnt how to insert a node to a BST in code. Here, I setup the root node/parent.
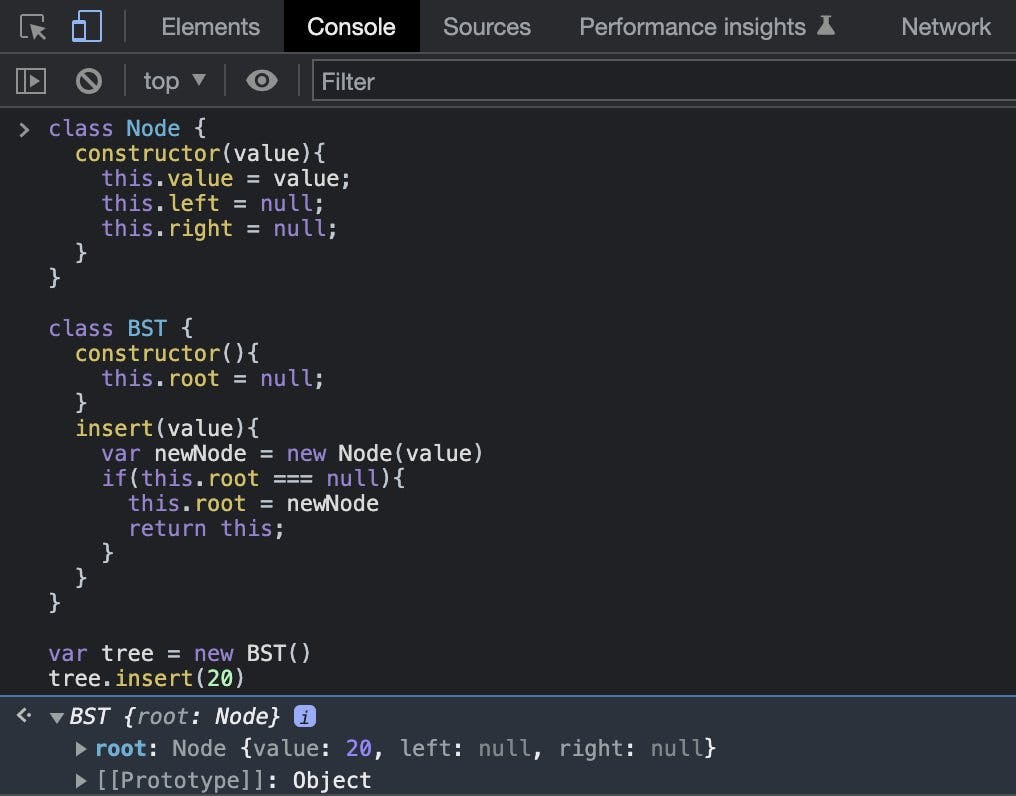
#30daysofDataStructures
Day 11 - #30daysofDataStructures 𝙸 𝚍𝚒𝚍 𝚗𝚘𝚝 𝚍𝚘 𝚊𝚗𝚢𝚝𝚑𝚒𝚗𝚐 𝚛𝚎𝚕𝚊𝚝𝚎𝚍 𝚝𝚘 𝚍𝚊𝚝𝚊 𝚜𝚝𝚛𝚞𝚌𝚝𝚞𝚛𝚎𝚜 𝚝𝚘𝚍𝚊𝚢😔
Day 12 - #30daysofDataStructures I practiced how to insert a node to the left and right side of BST and also how to search for a node using find/contains. I also had a call with a friend @Paultrig_py who explained some terms related to Trees, terms like Pre-order, In-order and Post-order. Thank you @Paultrig_py 🙏🏽
Day 13 - #30daysofDataStructures It's Sunday, I did a revision of everything I learnt last week😊
Day 14 - #30daysofDataStructures Tree Traversal: this has to do with visiting each node in a tree once.
There are two categories of tree traversals.
- Breadth First Traversal
- Depth First Traversal There are 3 patterns to visit the nodes in a tree and these patterns are unique because of the order in which they're used to visit each node in a tree.
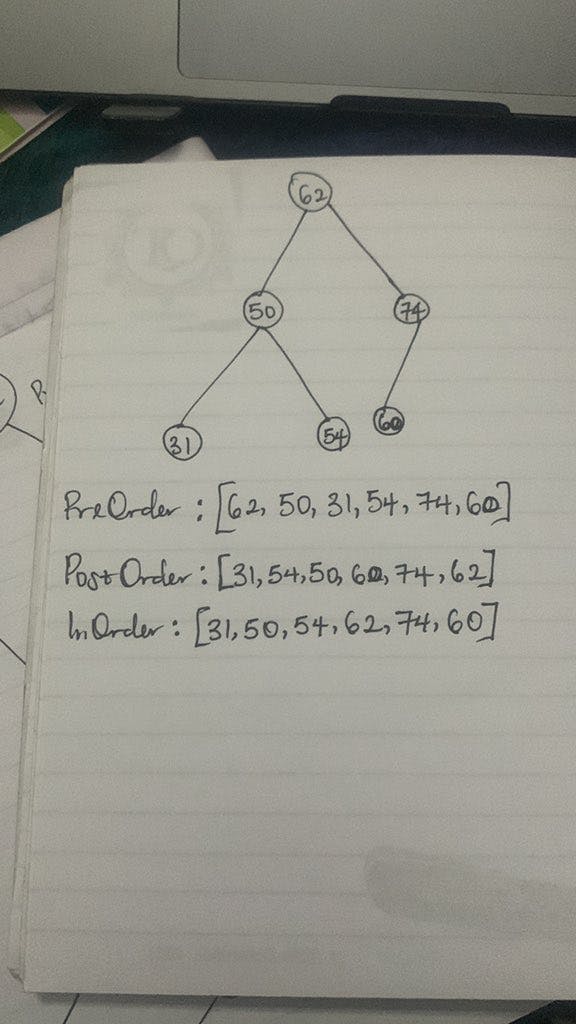
PreOrder, PostOrder and InOrder
Using the PreOrder pattern, a node can be visited from the "Root, everything on the left then everything on the right".
PostOrder pattern, "everything on the left starting from the last node on the left, the right then the root".
InOrder pattern, "everything on the left, the root then everything on the right".
The three patterns are under the Depth First traversals.
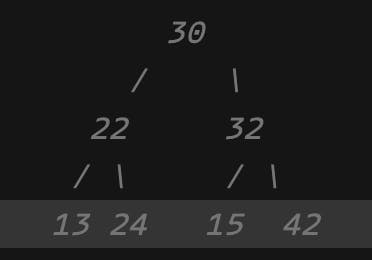
Day 15 - #30daysofDataStructures Heap is another category of Tree, it takes all the characteristics of a tree but is unique in its own way.
I focused on the Binary Heap, it's similar to a Binary Search Tree but has different rules.
The 2 examples of a Binary Heap are MaxBinaryHeap and MinBinaryHeap. MaxBH:
- the parent nodes are always greater than the children nodes in value.
- It doesn't matter if it's the left or right side of the heap.
- The root node takes the highest value.
MinBH is the opposite of MaxBH.
Arrays can be used to store a Binary Heap. To find the child node given the index of the parent node n, multiply the parent node by 2 and add 1. Left child is stored at : 2n + 1 Right child of parent node is stored at : 2n + 2 To find the parent, given the child node, the parent is at index (n - 1) / 2 and if we get a decimal number, we'll have to floor it.
Heap is interesting!!
#30daysofDataStructures
Day 16 - #30daysofDataStructures MaxBinaryHeap insertion and extraction.
Day 17 - #30daysofDataStructures I'll be taking a break to work on a personal project.
I hope to continue soon.